Сегодня в 3:50 мой VPS в Hetzner подох, при чем подох капитально. Сервер был недоступен ни по http, ни по ssh, даже не пинговался. В таком состоянии сервер провисел до утра, т.к. саппорт у Хетцнера ночью не бдит, а спит, ведь Хетцнер славится своими дешманскими ценами, и ясно дело экономия получается за счет уменьшения количества обслуживающего персонала.
Итак, найдя утром свой сервак нерабочим, я зашел в robot и попытался его перезагрузить. Но страничка перезагрузки выдавала ошибку:
The server details could not be determined due to an internal error.
Please contact our support team by using the contact form on the support page.
Бегло осмотрев другие возможности админки я понял что сам не разберусь и написал в саппорт. Погуглив в инете проблему нашел другого чувака, у которого в это же время также упал сервак в Хетцнере :)
Саппорт Хетцнера выходит на работу в 8 утра по центрально-европейскому времени, это в 14 по Бангкоку. В 15 часов в админке страничка перезагрузки стала доступна, видимо админ что-то починил, и я смог перезагрузить сервер. Это не помогло. Тогда я зашел в remote desctop, на страничке перезагрузки есть такая кнопочка снизу. При нажатии на неё откроется html-страничка с Java-апплетом, в котором можно в реальном времени увидеть что происходит «на экране» вашего сервера. На моем было вот это:
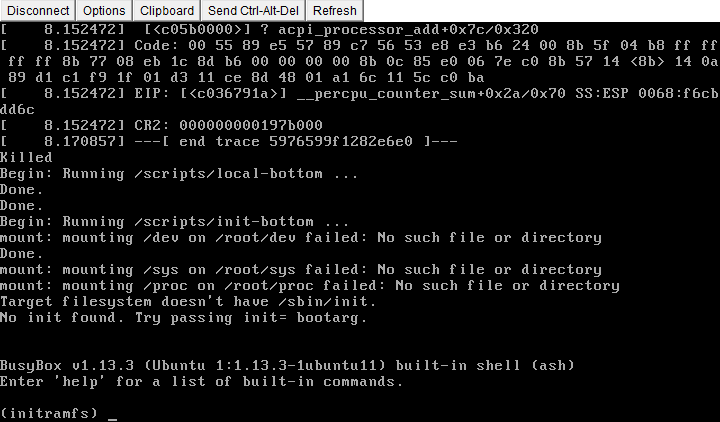
Что поставило меня в ступор. Пока я гуглил на тему саппорт отписал что мне нужно проверить диск из rescue mode. Что это такое? Rescue mode это режим при котором ваш сервер загрузит операционку по сети, вы сможете примонтировать ваше железо, и сделать нечто в реалиях вашего сервера без загрузки его собственной ОС. В моем случае мне нужно было проверить hdd.
Мастер из саппорта снабдил меня мануалом, который оказался не совсем точным. В моем случае нужно было сделать так:
fsck -C0 /dev/hda2
fsck -C0 /dev/hda3
После этого:
reboot
И сервер после перезагрузки загружает уже вашу ОС. После этого все работало как и раньше.
Время простоя сервера составило 9 часов. Время ответа саппорта 1:57 с момента их появления на рабочем месте.
Т.к. именно такая же ситуация уже имела место быть летом встает вопрос, либо о переезде, либо о создании полнофункциональных копий сайтов на клауде, с некой балансировкой. В случае отказа основного сервера весь трафик бы отправлялся в клауд на время простоя основного сервера, который работал бы до момента устранения поломки, затем перекачивал измененную БД на основной сервер. Т.к. тарифы на клауды обычно зависят от использования CPU и трафика, то должно быть дешево. Пока думаю про балансировщик.
Рекомендую еще интересное:

Если вам понравилось, пожалуйста, не поленитесь кликнуть «мне нравится» или «поделиться» или «+1» чуть ниже, или кинуть ссылку на статью в свой блог или форум. Спасибо :)
Вы можете оценить эту статью: 
![]() Загрузка...
Загрузка...
Не клоуд не вариант, но мысль интересная.
Для меня клоуд на 100% дорого, поэтому извращаемся с впсом :)